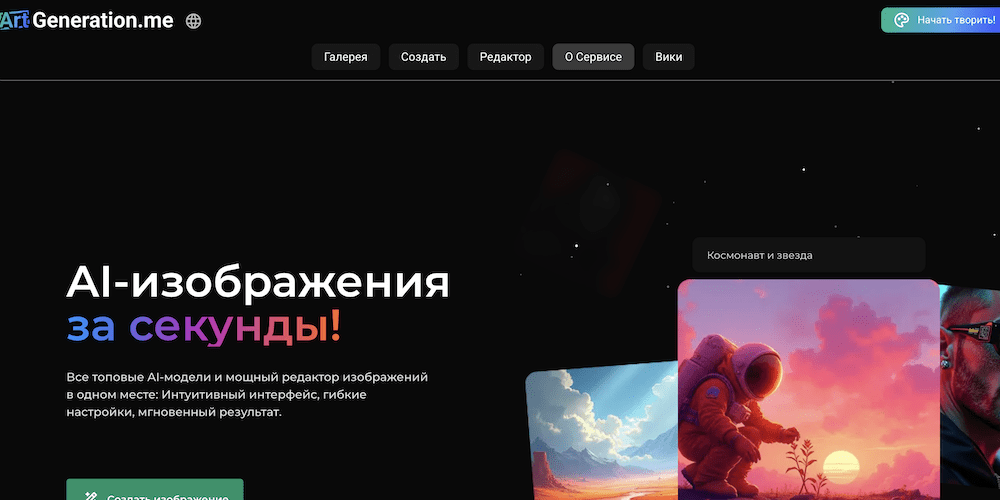
DALL-E генерирует изображения из текста
DALL-E — это искусственный интеллект, который создает изображения из текстовых описаний. Он использует глубокое обучение для понимания и усвоения текстовых команд, создавая соответствующие высококачественные иллюстрации. От простых концепций до более абстрактных идей — DALL-E способен преобразовывать текстовые инструкции в визуально связные изображения.
Редактирование изображений на основе искусственного интеллекта
DALL-E предлагает простой в использовании пользовательский интерфейс.
Dall-E использует сложную нейронную сеть под названием CLIP (предварительная тренировка контрастного языка и изображения) для обработки текстовых инструкций и преобразования их в изображения. Когда получена текстовая инструкция, Dall-E использует обучение на огромных наборах данных для создания изображений, соответствующих данным инструкциям. Помимо создания изображений с нуля, Dall-E также предлагает функции редактирования изображений, позволяющие добавлять новые визуальные элементы к существующим изображениям или расширять холст, создавая связанные визуальные эффекты для исходного изображения. Доступ к Dall-E осуществляется через графический интерфейс пользователя или API, и пользователь сохраняет все права на созданные изображения.
Чтобы проиллюстрировать вариант использования Dall-E, предположим, что вы хотите создать изображение для публикации в блоге о чтении в космосе. Вы могли бы дать Далл-И инструкцию типа «астронавт читает книгу на Луне». Затем программа будет использовать свое обучение для создания изображения, соответствующего этому описанию, не требуя с вашей стороны какого-либо кода или технических инструкций. Если позже вы захотите изменить это изображение, например, добавив другого человека или объект, вы можете использовать интерфейс редактирования, чтобы добавить дополнительные инструкции, например «добавить робота, подающего чай». Затем Dall-E создаст новое изображение, гармонично включающее эти новые элементы.